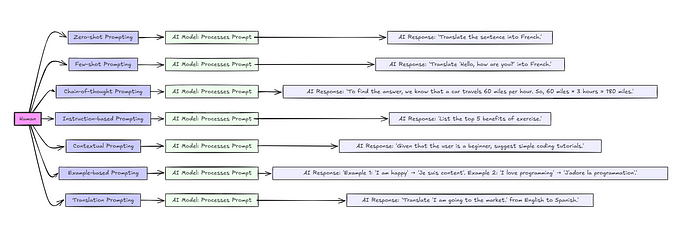
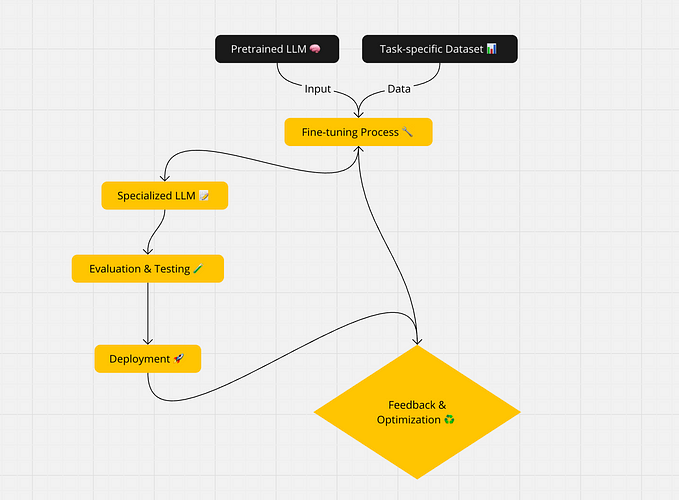
Experiments as an LLM developer
As primarily a back-end developer (read Java, Python, Golang!), it’s been interesting to observe about how LLMs have become mainstream in the last few months. Having said that, personally, I have struggled to separate the ‘hype’ (“AI can do everything!”) to realistic, practical applications of AI/LLM. And so, the curious mind inside me started ticking and getting keen to do some level or experiments with LLMs and LLM-based frameworks. This article is a collection of my learnings — on how to start with the basics of LLMs (aka the ‘hello world’ equivalent) and how to evolve the usage into some more sophisticated and interesting use-cases.
The following article walks through these experiments and my attempt to simplify their usage for practical applications.
The logistics
In order to use the publicly available GPT model, you will have to do the following steps:
- Log in / Create an account on https://platform.openai.com/ — this is the developer portal of openai where you start the OpenAI journey

2. Once logged in, create an API key on https://platform.openai.com/account/api-keys — you should treat these API keys as passwords and so, do not share these API keys with others

3. With your newly minted API key, you are good to go!
The pre-requisites
To kick-off the experimentation, you need a basic level of coding experience and no/minimal local setup.
You will need Python installed locally and optionally, a Jupyter notebook environment on your local machine — that’s all you need to get started! If you do have any constraints getting those two pre-requisites sorted, you can skip the local setup and directly use an online-hosted Python notebook for free — one such resource for that would be using the embedded Juptyer notebook available on:
https://learn.deeplearning.ai/langchain/lesson/1/introduction
Experiment 1 — Hello world!
Let’s talk through the ‘Hello World’ example of using OpenAI’s LLM model.
- Define a code block that will fetch the API key that you have stored in a
.envfile and set it to theopenai.api_keyvariable
import os
import openai
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']2. Define which particular LLM you plan to use — not that most examples that walkthrough that set a conditional model to overcome the deprecation of LLM model
import datetime
# Get the current date
current_date = datetime.datetime.now().date()
# Define the date after which the model should be set to "gpt-3.5-turbo"
target_date = datetime.date(2024, 6, 12)
# Set the model variable based on the current date
if current_date > target_date:
llm_name = "gpt-3.5-turbo"
else:
llm_name = "gpt-3.5-turbo-0301"3. Connect to OpenAI by passing the prompt, defining the role of the AI model — to fetch & print the response
prompt = """
I want you to greet how any first
computer science program usually greets the world,
followed with a smiley
"""
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=llm_name,
messages=messages,
temperature=0,
)
response.choices[0].message["content"]4. And sure enough, the response that we get is…

Experiment 2— Hello world using LangChain!
Using OpenAI APIs is a good start point but, we will quickly realise that we need a framework to do any sort of decent orchestration, pre-processing and post-processing. Luckily, LangChain is a pretty standard framework built and used by the community. This experiment is to do the above ‘Hello World’ example but using LangChain
- Steps #1 and #2 above will be exactly the same — define a code block that will fetch the API key and define the LLM model
import os
import openai
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']
import datetime
# Get the current date
current_date = datetime.datetime.now().date()
# Define the date after which the model should be set to "gpt-3.5-turbo"
target_date = datetime.date(2024, 6, 12)
# Set the model variable based on the current date
if current_date > target_date:
llm_name = "gpt-3.5-turbo"
else:
llm_name = "gpt-3.5-turbo-0301"2. Create the LangChain’s ChatOpenAI object
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI(temperature=0.0, model=llm_name)3. Connect to OpenAI by passing the Human Message — to fetch & print the response
from langchain.schema import HumanMessage
prompt = """
I want you to greet how any first
computer science program usually greets the world,
followed with a smiley
"""
message = HumanMessage(content=prompt)
chat([message]).content4. And sure enough, we get the same response as we did before…
Experiment 3 — chatting to a PDF
Next step — let’s feed the GPT model some new data and see if it is able to digest that information and then, respond to questions
- Fetch OpenAI API key from the environment
import os
import openai
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']2. Load the ‘new data’ — in my first example, I am using a 89-pages PDF that explains the rules of Cricket
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("https://www.lords.org/getattachment/MCC/All-Laws/2nd-Edition-of-the-2017-code-2019.pdf")
documents = loader.load()3. Splitting this PDF into chunks to be able to vectorise it before storing it into a vector store
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)
docs = text_splitter.split_documents(documents)4. Load the split document(s) into Chroma, which is an in-memory vector store. Note the use of an open-source embedding function
from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain.vectorstores import Chroma
embedding_function = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
db = Chroma.from_documents(docs, embedding_function)5. Define the LLM model and use the langchain OpenAI abstraction
import datetime
current_date = datetime.datetime.now().date()
if current_date < datetime.date(2023, 9, 2):
llm_name = "gpt-3.5-turbo-0301"
else:
llm_name = "gpt-3.5-turbo"
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model_name=llm_name,
temperature=0)6. Create the chain with already defined LLM model and the database
from langchain.chains import RetrievalQA
retrievalQA = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=db.as_retriever(),
verbose=True
)7. Ask the question and display the response!
from IPython.display import display, Markdown
prompt = "According to given context, create a list of the different ways a batsman can get out"
response = retrievalQA.run(prompt)
display(Markdown(response))8. And just like that, it was able to give the response as…

Experiment 4 — chatting to a YouTube video
The final experiment is to load a YouTube video and then, ask questions to the video — this was my lazy way of getting a summary! Interestingly, there are only 2 steps from Experiment 3 that need to change for this — so, i will write down only the deltas
- For #2 above, instead of loading the PDF, we load the YouTube video
from langchain.document_loaders.generic import GenericLoader
from langchain.document_loaders.parsers import OpenAIWhisperParser
from langchain.document_loaders.blob_loaders.youtube_audio import YoutubeAudioLoader
import openai
urls = ["https://www.youtube.com/watch?v=23DINwD33rA"]
# Directory to save audio files
save_dir = "yt-audios/"
loader = GenericLoader(YoutubeAudioLoader(urls, save_dir), OpenAIWhisperParser())
documents = loader.load()2. For #7 above, we ask a different question and get the correct response
from IPython.display import display, Markdown
prompt = """Answers based on the provided context.
Which car model is this review about?
What is the overall summary about Nissan Juke?
Tell me the top 3 positives and top 3 negatives
"""
response = retrievalQA.run(prompt)
display(Markdown(response))3. And just like that, it was able to give the response as…

Conclusion
Using LLM models in my experiments has been much more easier than what I had expected. LangChain does an amazing job of providing a framework for the orchestration and the chaining.
In case you want to check out the Python notebooks and have a play, all the source code from this article is available on https://github.com/kaushikchaubal/llm-experiments/tree/main